











We are in the midst of an election season that has rewritten the way politicians view the history books, shifted how Americans look at their fellow citizens, and created seemingly unsurpassable rifts between them. However, regardless of whether a voter is riding the Trump Train, feeling (felt) the Bern, or is with Her, one basic curiosity looms at the back of their mind: who’s going to win?
It’s a question that has long drive people in political science and statistics to find models, polling methodologies, and patterns in history to create models that can accurately and consistently predict the results of presidential elections. More recently, people in computer and data science have started to enter the field, wielding new tools, such as neural networks, machine learning, or advanced statistical analysis, to harvest new kinds of information from the same old data.
Predicting an election is not an easy task. It requires foretelling the beliefs and the intentions of well over 100 million people, months in advance, well before many of them have even made up their minds on who they will vote for.
The first step in creating an accurate prediction model involves choosing the appropriate data source. In a standard election, political forecasters like to use historical economical data to predict the outcome, often with good results. For example, in 1988, Michael Dukakis led in the polls against George Bush Sr. for much of the campaign season. But models considering the strong economy at the time and the fact that Bush was the Vice President of a popular incumbent president, Ronald Reagan, predicted that Bush would eventually come up on top and win the election (which he did).
But of course, there is hardly anything that could be considered “standard” about this election.
Thanks to a full year that has thoroughly broken all traditional theories on political science and is beckoning an entirely new era in American political history, predicting based on the past has suddenly become much less reliable.
Due to the historical unpopularity of both major candidates for president, these traditional avenues of prediction have been deemed inapplicable to this cycle, even by their creators. As a result, we have to turn to sources of data from the present, rather than from the past, to try to predict the future.
The most well-known political forecaster actively predicting this year’s election is Nate Silver, thanks to his past successes in predicting elections. After being named one of the World’s 100 Most Influential People in 2009 for correctly predicting the results of 49 out of 50 states in the 2008 presidential election, he went on to predict the 2012 election without missing a single state.
Nate Silver’s models mostly use poll data to calculate the probability of each candidate winning, as laid out in these steps:
- Step 1: Collect, weight and average polls.
- Step 2: Adjust polls.
- Step 3: Combine polls with demographic and (in the case of polls-plus) economic data.
- Step 4: Account for uncertainty and simulate the election thousands of times.
The most important factor here is the averaging of the polls. Media outlets love to report outlier polls showing one candidate or another up in the polls by a surprising amount, implying that something significant has changed about the election based on just one poll.
However, due to the uncertain nature of polling, it is expected for individual polls to sometimes be wildly apart from one another, in the same way you would expect that in a random group of people, some of them are much taller than others. Averaging polls helps eliminate these statistical errors and allows for predictions that have a smaller margin of error than the polls on which they are based.
However, even Nate Silver’s models, and therefore the polls, have had trouble making sense of this election.
This entire election cycle has been wrought with endless scandals, controversies, and leaks draping negativity over both candidates. Public opinion polls have shifted rapidly as news cycles shift from one candidate to the other, one scandal to the next, giving a very noisy picture of the race over time.
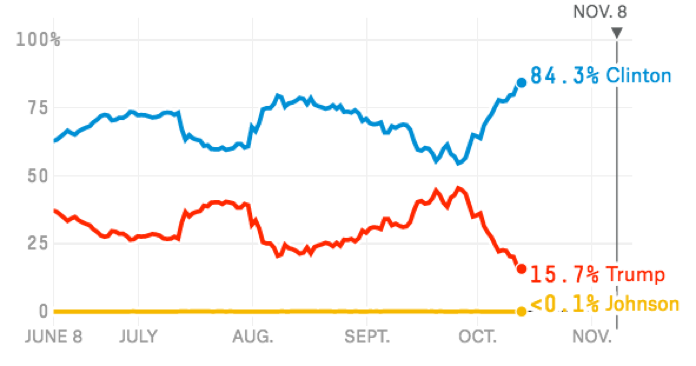
Nate Silver’s Polls Plus predictions from June 8th through October 12th
Nate Silver’s Polls Only model, which doesn’t account for convention bounces or economic factors, has had an even bouncier cycle.
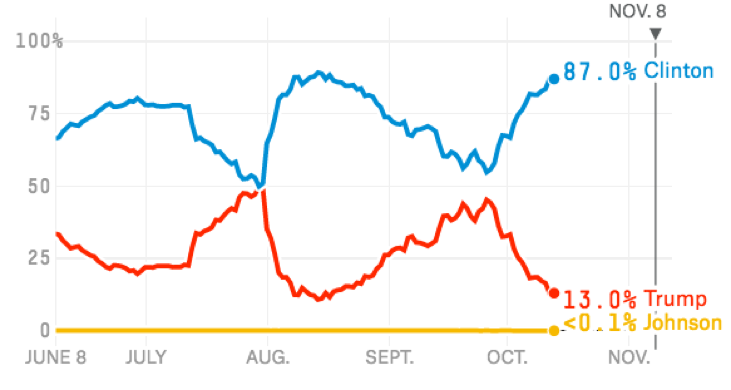
This isn’t a fault of Nate Silver’s or his models, but rather the nature of the poll data they rely on. Rapid-speed news cycles combined with the abnormally high number of undecided and third-party voters that will eventually support one of the mainstream candidates creates a huge amount of ripples in public opinion and the polls.
But what if we want a crystal ball that looks past all that volatility and makes a concrete prediction of the future that we can trust now, and two weeks from now as well?
Prediction Markets
Prediction markets are these peculiar online websites where thousands of traders place bets on elections or other political events in the same way a gambler might bet on a certain horse winning a horse race. Betfair and PredictIt are two of the more popular prediction markets.
Through the power of the financial incentives created by these websites, prediction markets offer a powerful way to calculate the true odds of an election. They operate as data aggregators in similar fashion Nate Silver’s models in order to create predictions., but However, instead of crunching raw numbers to create the probabilities of each candidate winning, they are powered by thousands of people crunching a combination of data, news events, and personal perceptions.
These markets tend to be more stable than polls or poll-based markets. The graph below taken from PredictWise, a website that aggregates prediction markets into actual predictions, shows just how stable these markets are even in the face of multiple conventions, scandals, and blunders taking up the news cycles for weeks on end.
Compared to the data from Nate Silver’s Polls Only model over the time frame, these predictions are practically flat for much of the race, until both started converging towards Clinton after a series of leaks and accusations of sexual assault dramatically hurt Trump’s standing with women voters in the last few weeks.
So now we can predict the election in a relatively consistent manner (prediction markets), and directly see the beliefs and opinions of the public (polls). But still, both polls and prediction markets have their flaws. Polls are slow to show changes in opinion, prone to bad methodology, and are not very useful individually. Prediction markets are able to update their odds in real time and are able to stabilize themselves despite large changes in the polls. But at the end of the day, they don’t offer any actual new data, merely a new option to consolidate what we already have into an actual prediction. What if we wanted to find a new data source that could tell us something that history, polls, and prediction markets could not?
The answer is simple–social media. The internet has exploded in the last few decades, with the last ten years bringing the rise of social media. and anEven since the first election of President Obama in 2008, the percentage of adults who use at least on social media site has skyrocketed from 25% to 65%, and social media grew from being just another distraction in our lives to an extension of our personalities. A useful side effect of all this growth has been an exponential increase in the amount of data people create, share, and enjoy with each other using social media websites such as Google, Facebook, and Twitter.
Political discourse wasn’t left out of this growth, making social media has a potentially ripe source for real time data on how people think and feel about certain politicians at any given time.! Although social media’s demographical bias towards younger people makes it a challenge to extrapolate trends to the general population, it can provide a window into how people’s thoughts, beliefs, and actions are changing in real time in a way polls never could.
The tricky part is teasing out the data from the unorganized mush of words that makes up what people say on the internet–people describe their feelings using words and links to articles mirroring their opinions, rather than the discrete and easy-to-understand data a poll or a prediction market provides.
This is where the technology and data analysis experts come in. With the use of cutting-edge natural language processing (NLP) techniques such as sentiment analysis, a sequence of words in a tweet, Facebook post, or Reddit comment that would otherwise be meaningless to a computer can be converted into a discrete numerical representation of how a certain person feels about a certain candidate based on that post. This representation could then be aggregated and fed into a model that could show changes in how candidates are perceived over time, by tracking changes in the average tone used about that candidate on social media. The data could even be trained to predict the results of new polls that are still being conducted, by training a model through supervised machine learning to predict them based on how older social media data correlated to old poll data.
Google Trends, a service provided by Google that aggregates and displays the relative popularity of any given search queries over time, provides a different lens on the same concept. Instead of seeing what people are saying, Google Trends shows us what people are trying to learn. When a large news event about one candidate happens, search queries about that candidate tend to increase proportionately to the magnitude of the event. The graph below comparing search trends of Donald Trump (red) and Hillary Clinton (blue) shows this in effect–queries of Hillary Clinton surged as the FBI investigation surrounding her private servers wrapped up, and interest in Donald Trump similarly spiked during the Republican Convention.
Google Trends
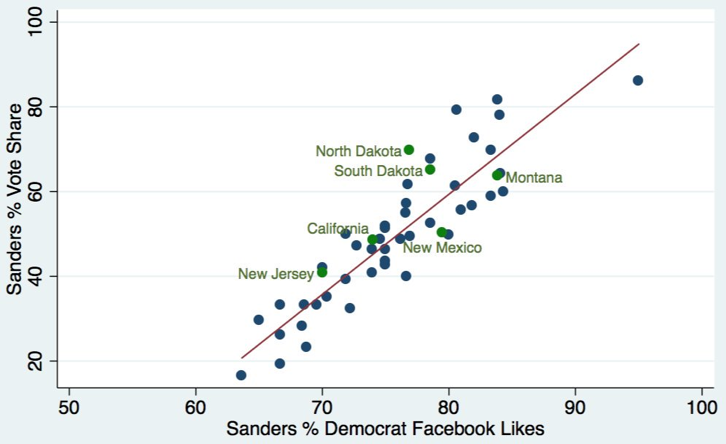
Social media platforms also provide more simple ways to view data about certain candidates that can be predictive. The graph below shows how the number of Facebook likes Bernie Sanders had in a particular state corresponded to his vote share in that state’s primary or caucus, with a surprisingly strong correlation.
 https://twitter.com/tylerpedigoky
https://twitter.com/tylerpedigoky
Despite the advantages of using social media as a data source, hardly anyone has been using it to make meaningful predictions.
With the continued emergence of new and robust data sources such as social media, breakthroughs in cognitive algorithms such as Natural Language Processing and Machine Learning, and increased computing power, it is now possible to create predictive models that approach problems with more complete perspective, and ultimately, human intelligence at machine scale.
For now, we’ll continue to follow Mr. Silver’s work while pushing the limits of cognitive security and predictive analytics in energy, security, and finance.


